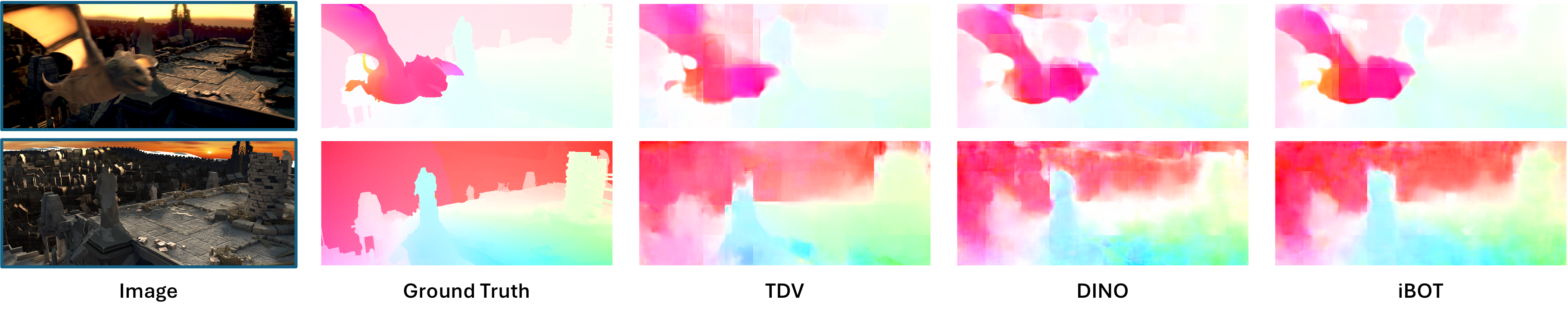Progress in the field of AI has largely been driven by methods that more effectively
leverage increasing computation and data. Generally, this takes the form of approaches
with weaker inductive biases or assumptions about the data performing
asymptotically better than approaches with stronger assumptions. This is particularly
characteristic in the field of Visual Representation Learning, where approaches have
gone from being dominated by Supervised Learning, to Weakly Supervised Learning, to
the eventual widespread success of Self-Supervised Learning without human labels.
Yet even modern Self-Supervised Learning approaches still depend on strong inductive
biases such as augmentations, masking, cropping, or raw data reconstruction. Notably,
we show empirically that the optimal strength of these inductive biases decreases as
data scale grows — motivating the search for approaches that rely on as few
assumptions as possible.
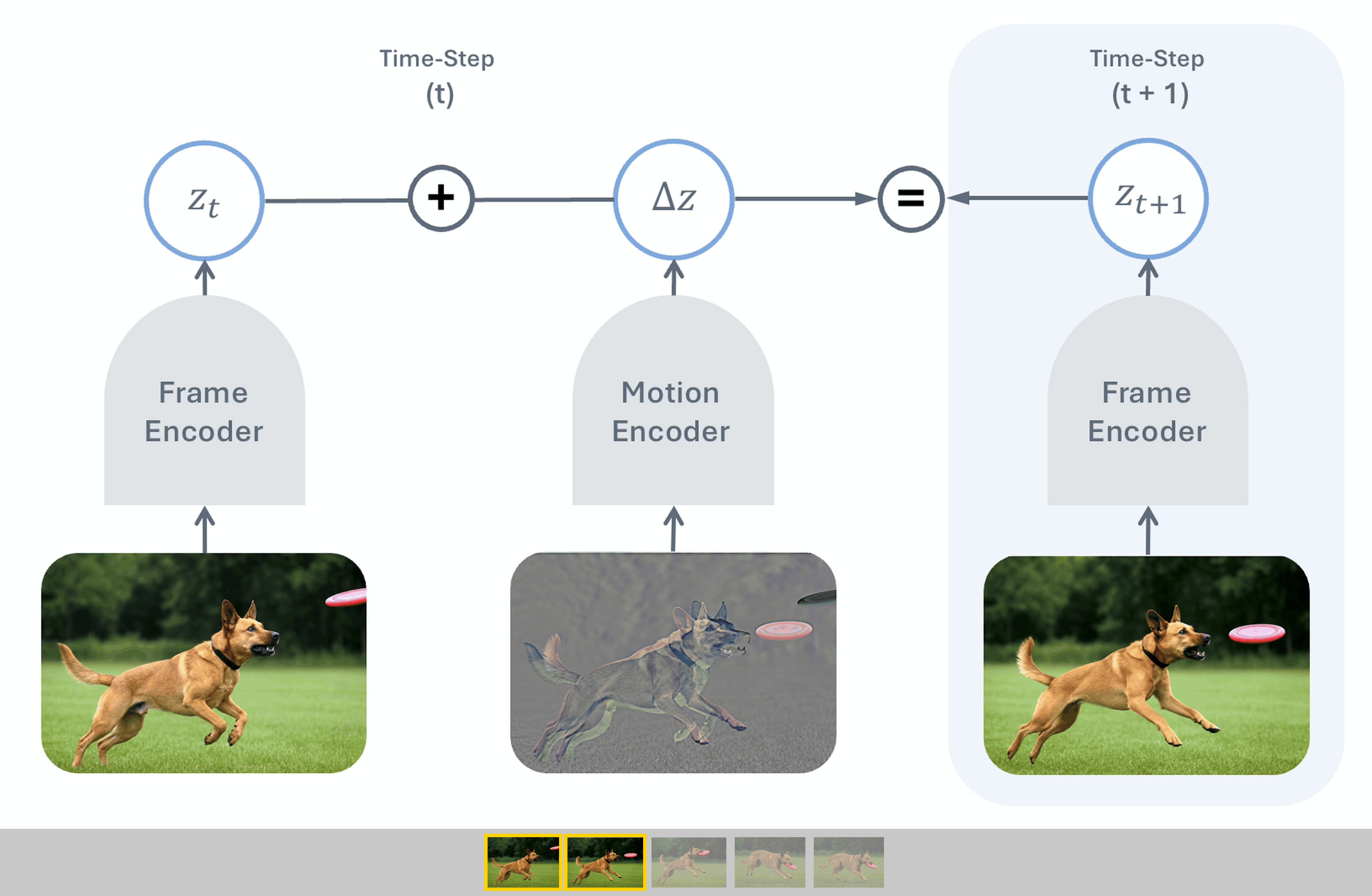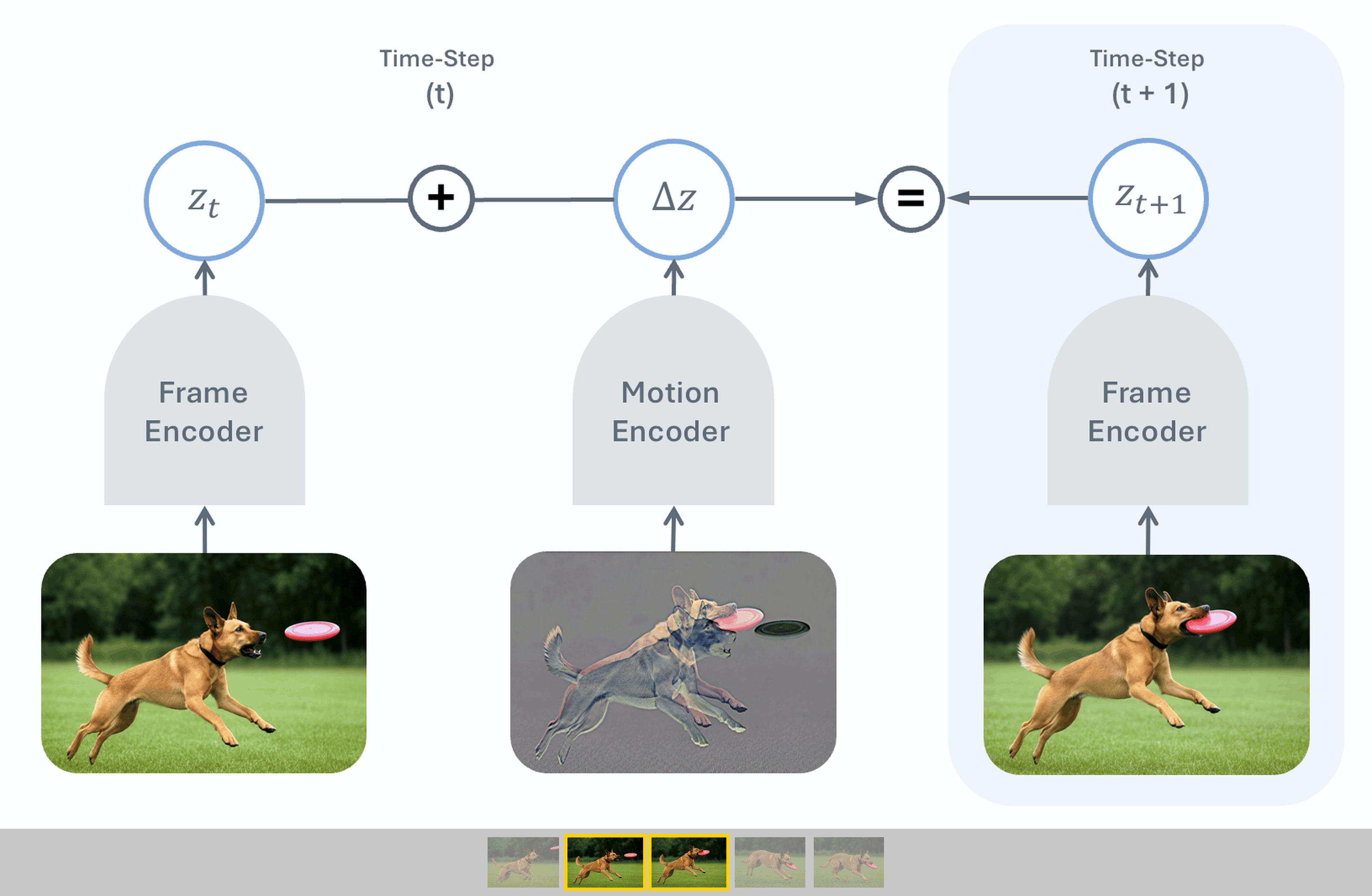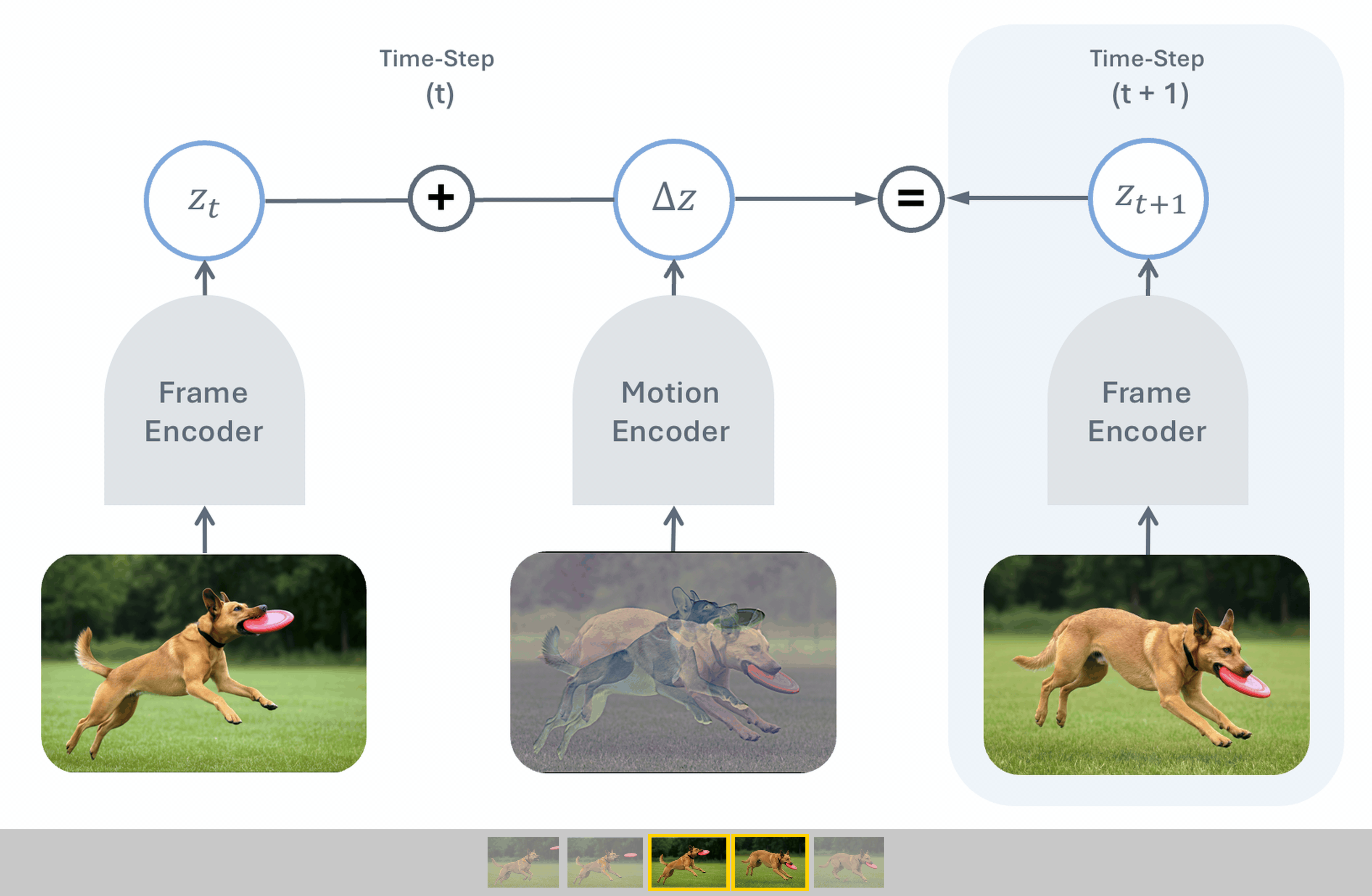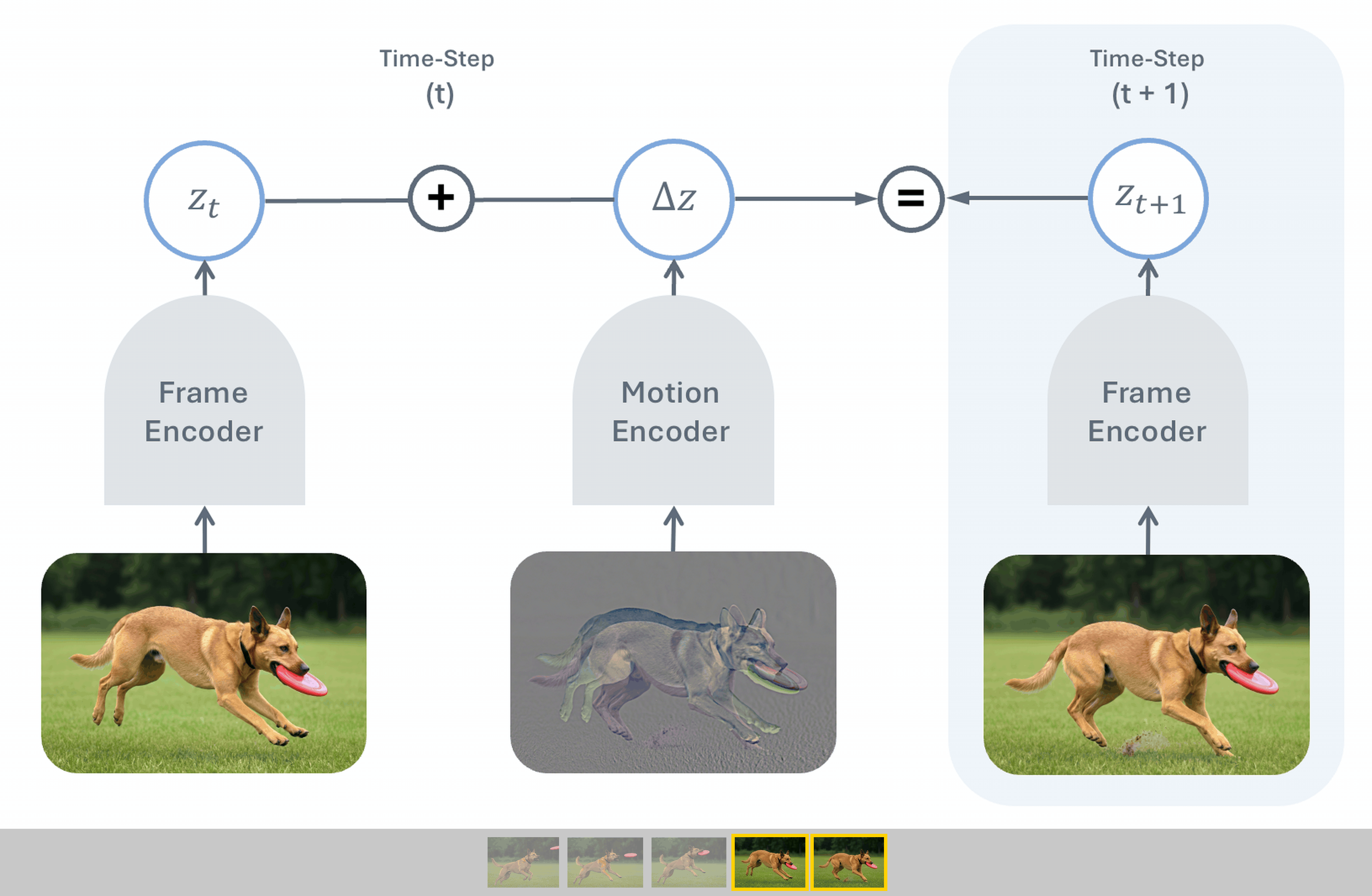
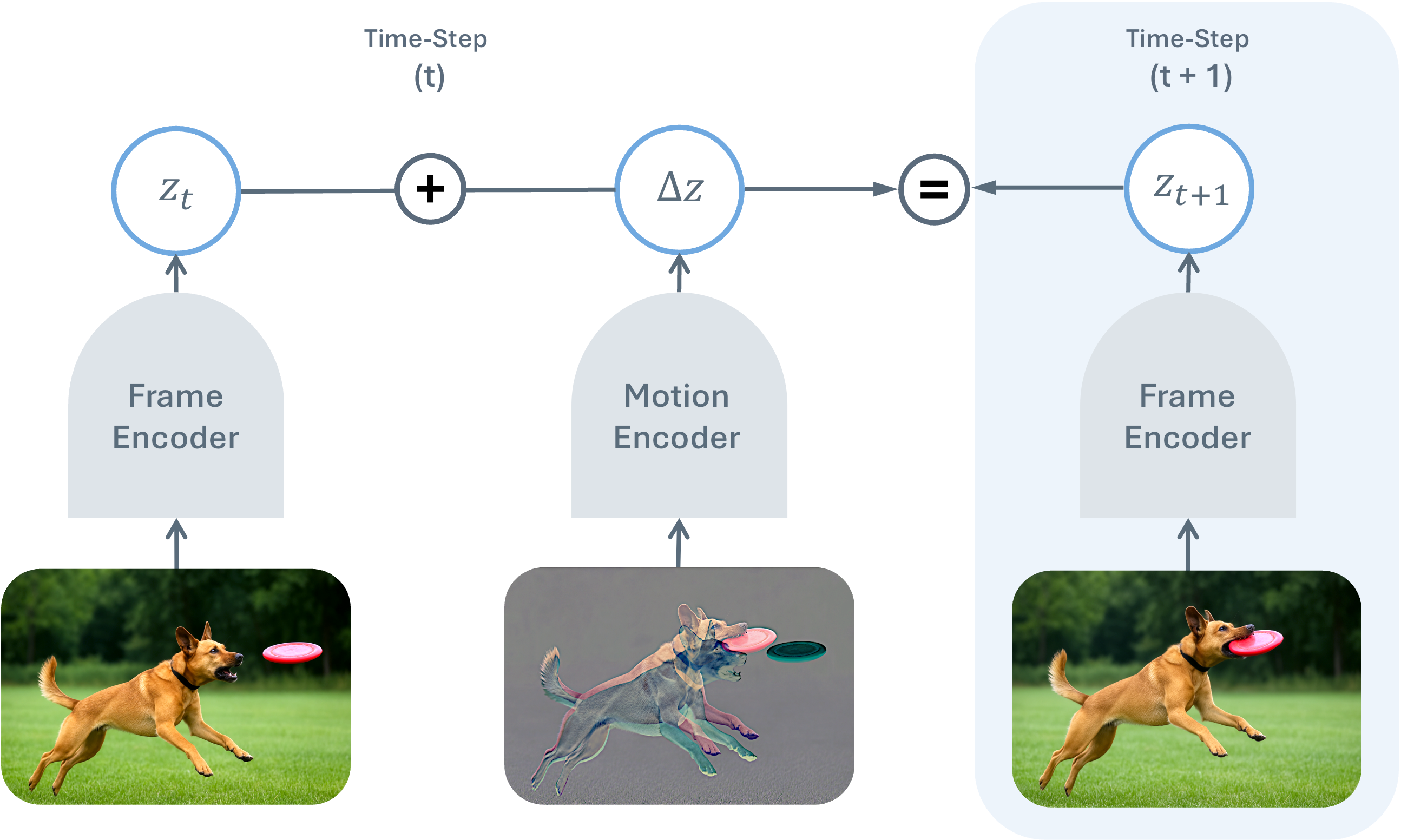
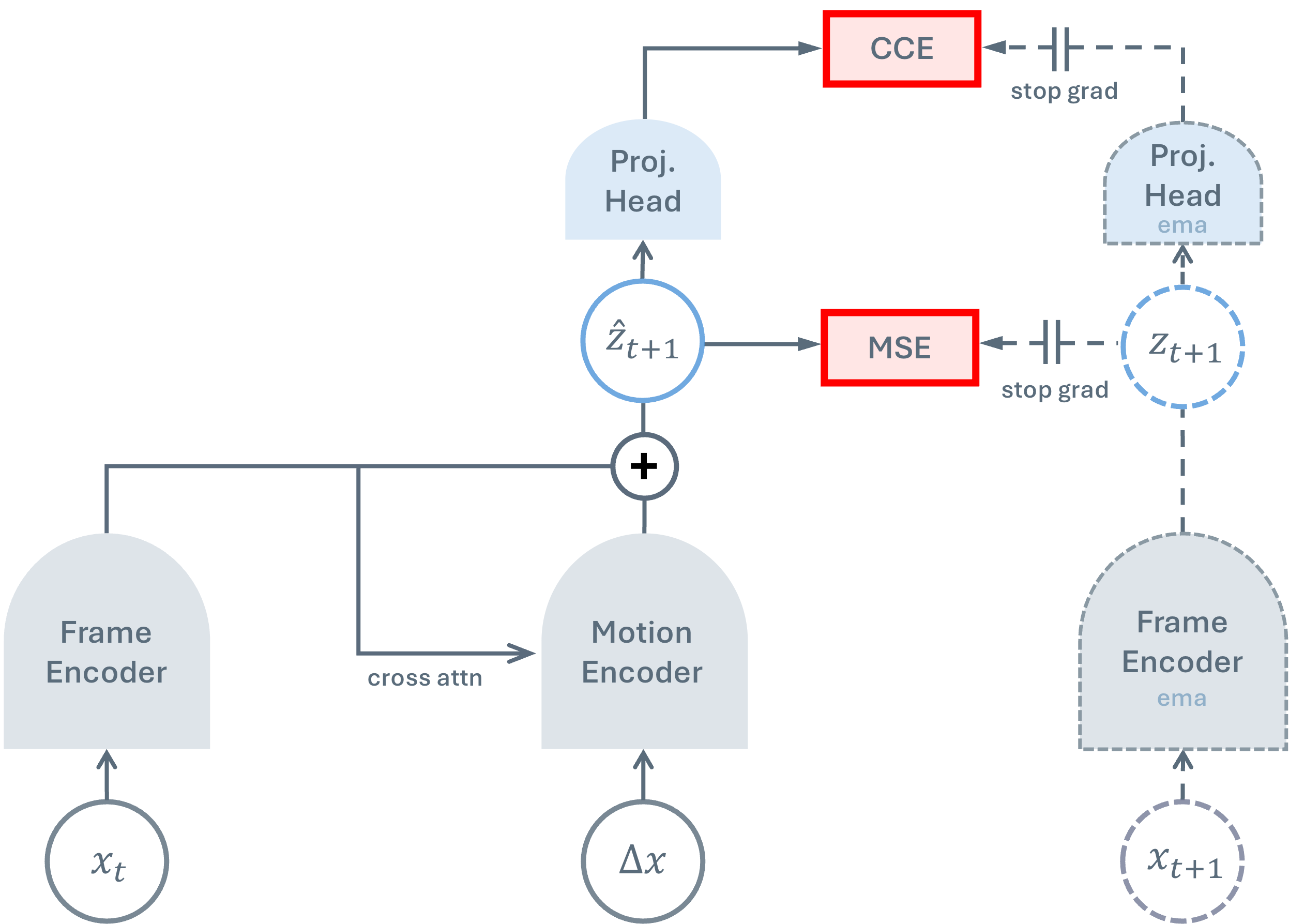
To push this frontier further, we introduce Temporal Difference in Vision (TDV),
a new approach for self-supervised learning from video that avoids the reliance on
existing inductive biases, relying instead on the causal assumption that the past
causes the future. TDV functions by jointly training an image encoder and a motion
encoder so that the current frame's representation plus the encoded motion equals the
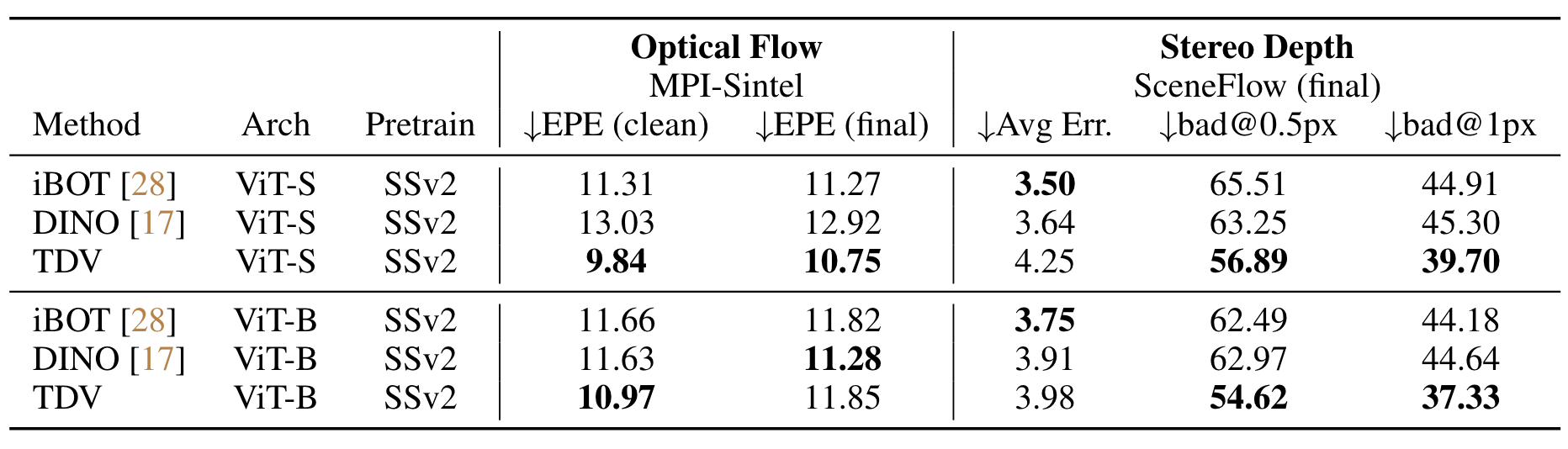
next frame's representation. Despite not leveraging any strong inductive biases, TDV
matches or surpasses state-of-the-art recipes on dense spatial tasks, laying the
foundation for representation learning with weaker assumptions.